
Gumbel-Softmax
Why are we interested in Gumbel-Softmax?
Gumbel-Softmax makes categorical sampling differentiable. Why is that important? Because sometimes we want to optimize discrete or categorical choices with gradient methods. One of the applications is that we can use it in differentiable neural architecture search when we want to decide the operation on one edge.
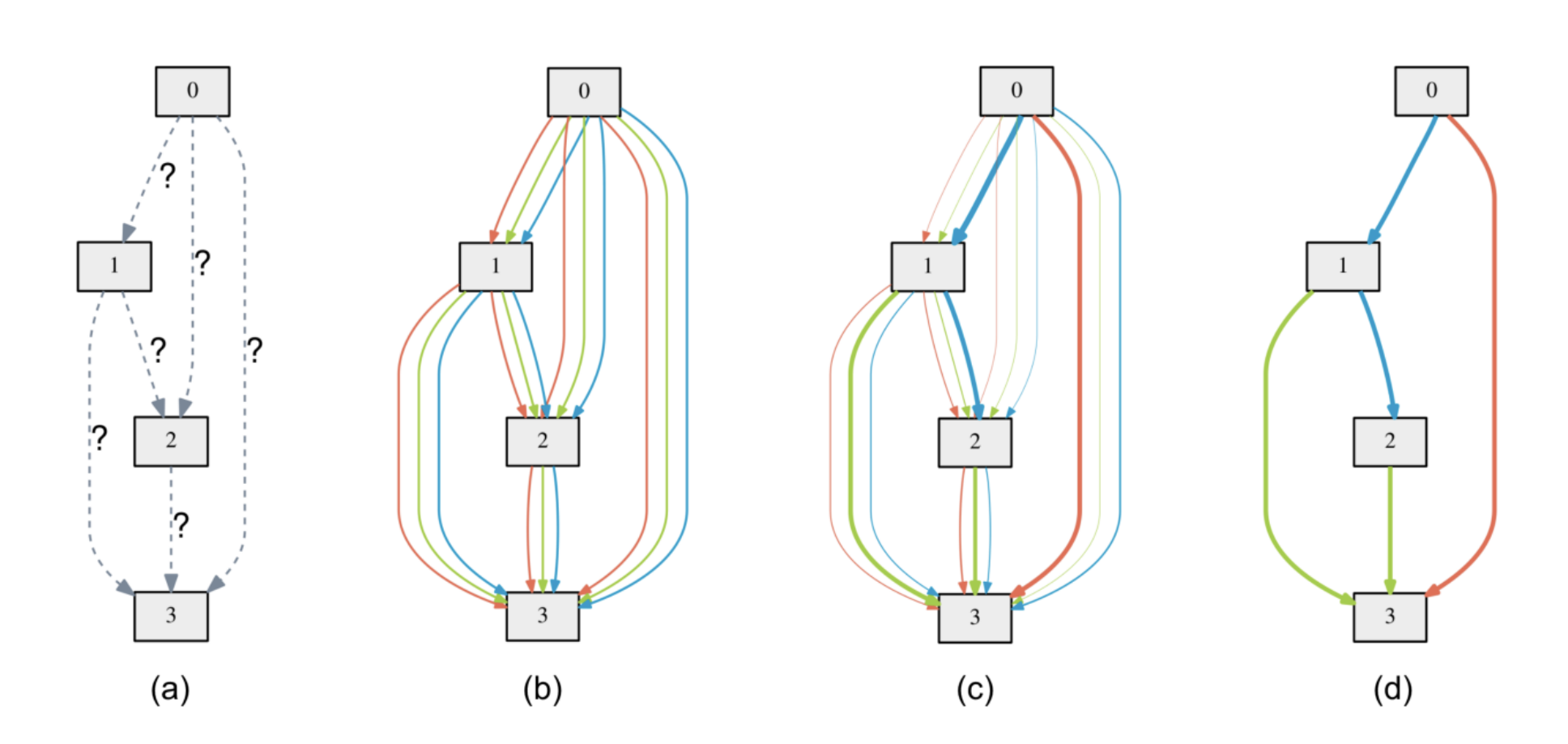 DARTS: Differentiable Architecture Search
DARTS: Differentiable Architecture SearchThe original DARTS paper did not introduce Gumbel-Softmax. To decide which operation should be on one edge, it does the following things:
- During search, the output of each operation is joined (weighted sum) with a group of learnable parameters (
, , …, ), is the number of operation choices), like the color lines in the above figure. - When search is done, a final architecture is derived, meaning that we have to choose an operation for each edge. How do we do that? We use
to choose the operation with the largest .
But, doing so causes a “gap”: the original network has a weighted sum of all operations during training, but the derived network loses all of the unchosen operation’s information, maybe the derived network has a different final performance than expected.
“If only we can train one network each time during search!” one might say. Indeed, selecting one operation for an edge during search instead of using a weighted sum is a good idea. But, sampling itself is not differentiable, we can’t update the parameters with gradient descent.
Don’t worry, Gumbel-Softmax is coming to rescue.
Gumbel distribution
First we need to understand what is Gumbel distribution.
Gumbel distribution stands for Generalized Extreme Value distribution Type-I. It is used to model the distirbution of the maximum of various distributions. Gumbel distribution is a particular case of the generalized extreme value distribution.
Gumbel distribution has two parameters:
: location : scale, larger leads to fatter distribution.
The PDF of Gumbel distribution is:
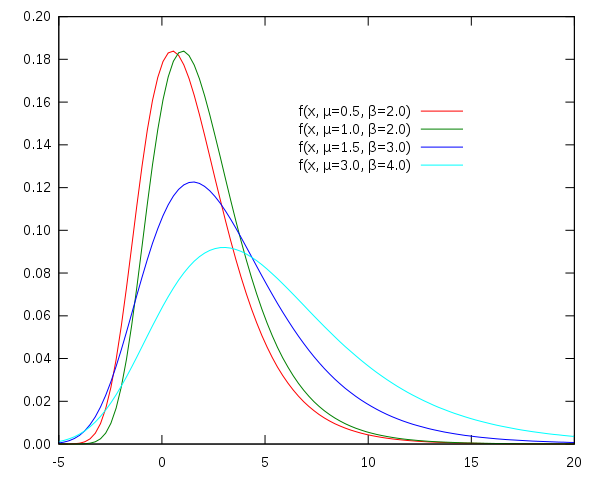
where
What is Gumbel-Softmax?
When we “choose an operation for one edge”, what we are doing is actually drawing a sample from a categorical distribution. A categorical distribution means a random variable can take the value of many discrete categories, with each case’s probability known.
Let’s say, we have a categorical variable
where
as
This is the Gumbel-Softmax trick.
Here we added a temperature variable
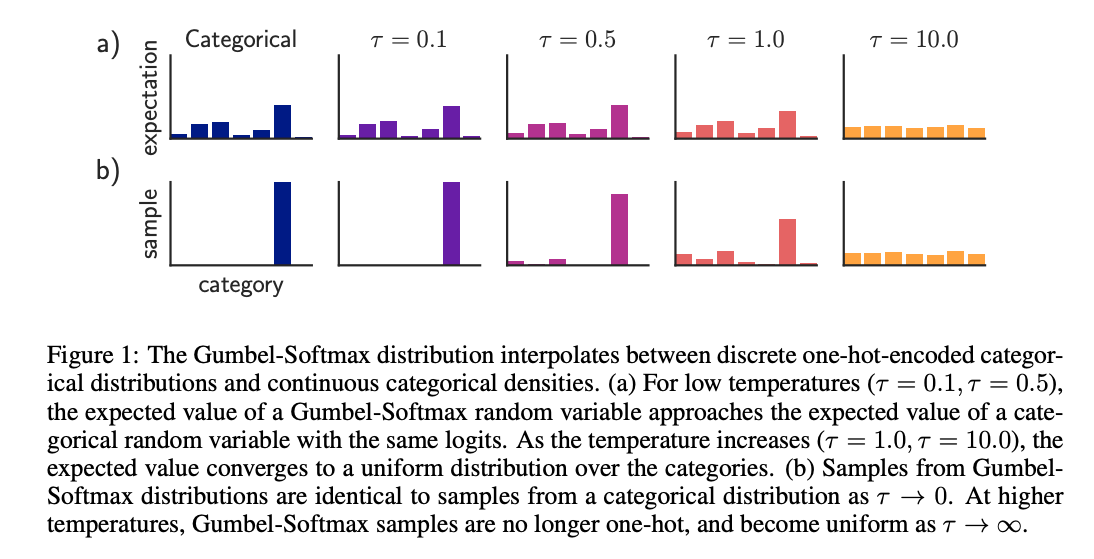
Let me explain. Softmax is just a normalized exponential function. At high temperature, every element
We can think of as heating a crystal. Higher temperature melts the crystal, it becomes more soft (closer to uniform distribution). When it cools down, it becomes hardened and sharp.
We often use an annealing schedule with softmax, starting from a high temperature and gradually cooling it down. This is because we want every choice of operator sufficiently trained at early stage, and gradually forms a preference at later stage.
The Gumbel-Softmax gradient estimator
In some literature we may see the jargon “Gumble-Softmax gradient estimator”. It is well explained in the original paper:
“The Gumbel-Softmax distribution is smooth for
Straight-through Gumbel-Softmax gradient estimator
“Straight-through” means that only backward gradient propagation uses the differentiable variable, the forward pass still uses categorical variable.